大家都知道ML最基本的就是資料的讀取,把資料輸入加速設備(GPU,TPU),在tensorflow裡讀取分為四大類分別為 tf.data,Feeding,QueueRunner,Preloaded data,然而我今天只會介紹tf.data,我自認為那是最容易架構出輸入管道(pipeline)。
輸入資料三個步驟
1.提取:從儲存的地方取得資料 例如:SSD或其他遠端儲存位置
2.轉換:使用CPU做資料的預先處理 例如:對影像作翻轉、剪裁和正規化等
3.載入:將轉換後的資料載入到機器學習模型的加速器
這三個步驟主要是裝置讀取資料和CPU預處理消耗的時間,如果沒有分配妥當會造成CPU在準備資料的時候,GPU閒著在等待訓練資料,相反的GPU在訓練資料CPU卻在空閒狀態,這樣會讓訓練的時間越來越長。
為了解決上述的狀況
Tensorflow提供tf.data API,讓使用者打造靈活有效的輸入管道。輕鬆處理大量資料,不同資料格式及複雜的轉換,並透過使用tf.data.Dataset.prefetch可以讓生成資料和訓練資料同時進行。
如果讀取的檔案過大或資料處理太久,只需要呼叫map方法時加入num_parallel_calls設定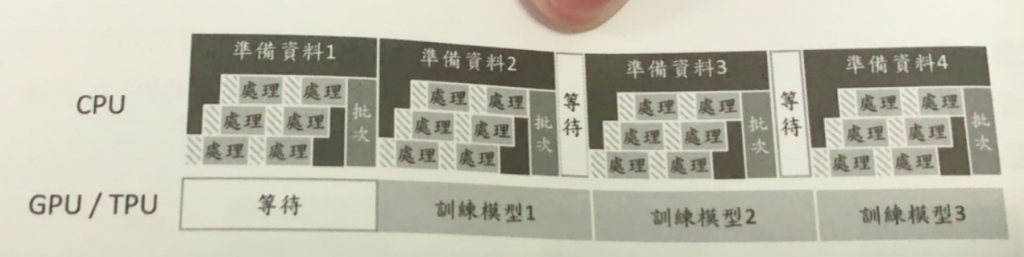
基本讀取資料的操作
使用Loop讀取資料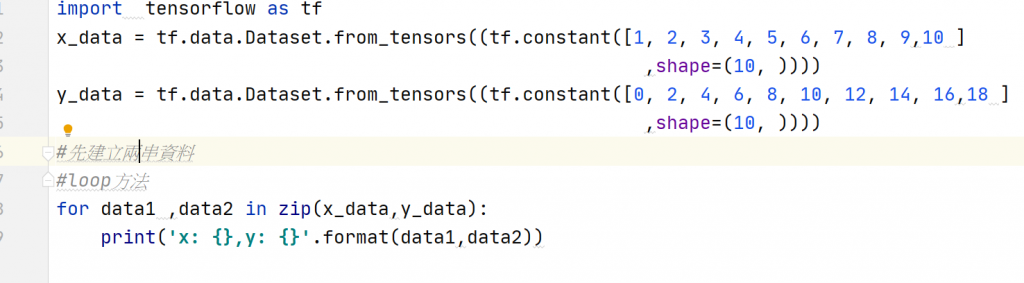
結果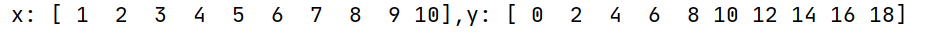
Tf.data.Dataset.zip
將多個dataset打包成一個
使用map來轉換資料
Shuffle
Dataset會被載入buffer中,並從buffer中隨機選取資料出來,取出資料產生的空位會從新的資料替補。而buffer_size是設定buffer大小,最好是設定大於或等於整個dataset的資料個數
當然了實際上讀取資料並沒有這麼簡單,還需要考慮許多的因素,之後我坐實作的時候再跟大家好好來解釋
參考
輕鬆學會google Tensorflow 2.0人工智慧深度學習實作開發

